我们在设计 Pin 时做了一个很小但很关键的决定:它不应该只是一个全局备忘录。
全局备忘录很容易做。给用户一个输入框,保存标题和正文,再按时间排序。很多工具都这样工作,也足够覆盖“稍后再看”的场景。
但 AI 编码里的问题不太一样。我们看到的瓶颈不是没有地方记事,而是几天后重新打开这件事时,原来的上下文已经散了。截图在聊天里,失败日志在终端滚动里,判断在一次 review 里,下一步动作只存在于人的记忆里。记录还在,但工作已经不可恢复。
所以我们把 Pin 设计成项目旁边的一块工作记忆。它要保存的不是一个想法,而是一段可以被继续执行的上下文。
交互式 agent 的上限
最开始使用编码 agent 时,交互式会话通常是最高效的入口。开一个终端,描述任务,等它执行,读结果,再继续下一轮。
这个模式在一两个会话里很好用。它足够直接,也保留了人的判断。
问题出现在并行度上来之后。我们发现,当一个人同时照看三到五个 agent 会话时,真正变贵的不是 agent 的运行时间,而是人的切换成本。你需要记住每个会话属于哪个 worktree、现在卡在哪一步、输出是否可信,以及它是不是发现了一个不该丢掉的后续问题。
这些后续问题很尴尬。它们通常是真实的,但又没有大到值得立刻打断当前任务。
比如:
- agent 修一个测试时发现一处命名已经误导了调用方。
- 你 review 一个 PR 时看到一个窄屏布局问题,但这不是当前改动的范围。
- 用户发来一张截图,问题很清楚,但你正在处理另一个分支。
- 一个实验方向失败了,不过失败原因以后可能有用。
如果这些信息只留在聊天记录里,它们会变成时间线的一部分,而不是工作系统的一部分。时间线擅长还原对话,不擅长承载未来任务。未来的你,或者另一个 agent,不应该从几十轮对话里猜“这件事到底要从哪里继续”。
视角转换:保存可恢复的工作
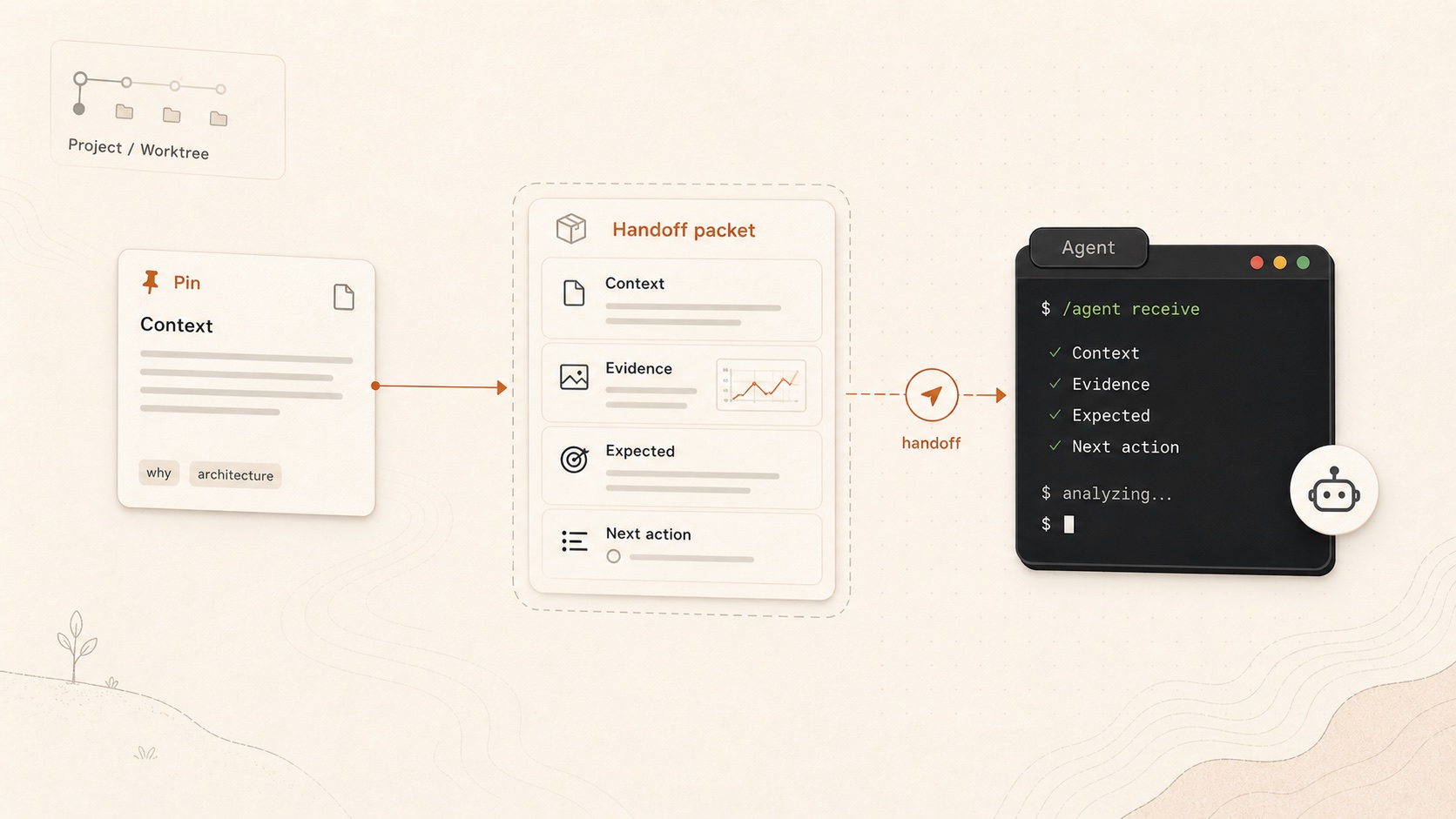
我们后来把问题重新表述了一次:Pin 不是用来保存内容,而是用来保存恢复点。
这个变化影响了产品的形状。一个恢复点至少需要四类信息:
- 背景:为什么这件事存在。
- 证据:截图、日志、链接或复现条件。
- 期望:什么结果算处理完成。
- 下一步:谁或什么 agent 可以从哪里开始。
这也是为什么一个好的 Pin 不应该只写成:
Fix login它更应该像这样:
Title: Fix the login button on narrow screens
Context: Reproduced in a 13-inch window. The primary button touches
helper text below it.
Evidence: Screenshot attached.
Expected: Keep stable spacing when the English copy wraps.
Next action: Ask an agent to locate the layout component and test the
narrow viewport.这不是为了把记录变重。相反,它是为了让未来的启动成本变低。上下文越完整,下一轮执行越不需要重新询问、重新翻日志、重新判断优先级。
为什么 Pin 要贴着项目
外部 todo 工具可以保存任务,但它通常离工作现场太远。
当你真正要处理一个条目时,还要重新找到仓库、分支、终端、截图、讨论和当前代码状态。对于普通待办,这是摩擦;对于 agent 工作流,这是质量问题。agent 拿到的上下文越薄,就越容易靠猜测补全。
TermCanvas 里的 Pin 是项目内的对象。它和 repo、worktree、terminal、agent 会话放在同一个工作面里。打开项目时,我们希望看到的不是“我曾经收藏过什么”,而是:
- 这个项目还有哪些线索没有闭环。
- 哪些可以直接交给 agent。
- 哪些需要人先判断。
- 哪些已经完成。
- 哪些被有意识地放弃。
这让 Pin 更接近一个轻量控制面。它不是完整的项目管理系统,也不应该替代 issue tracker。它处理的是更小、更早、更贴近上下文的一层:那些现在不做、但丢掉会损失判断成本的东西。
当一个 Pin 被交给终端或 agent 时,它就从记录变成输入。标题、正文、链接、截图和下一步动作一起构成 prompt 的起点。agent 不需要从当前聊天里“感受”你的意图,而是拿到一个明确的恢复点。
去中心化的工作记忆
Pin 还有一个容易被低估的特性:它不要求所有工作都进入同一个中心系统。
团队协作里已经有很多成熟的权限和共享界面。Linear 可以管理产品任务,飞书和 Notion 可以承载文档和讨论,GitHub Issues 可以贴近代码和 PR。它们都有自己的权限模型、通知机制和组织习惯。我们不应该用 Pin 重新发明这些系统。
更合理的方式是让这些工具继续做它们擅长的事:谁能看、谁能改、什么内容应该被共享、什么工作需要进入正式流程。Pin 负责另一层:把你在本地工作时产生的洞察、证据和下一步固定下来,并在需要时和外部系统连接。
这让 Pin 同时具备两种形态。
一种是个人的。本地 Pin 可以保存那些还没有准备好公开的判断:一次实验为什么失败、某个 agent 输出为什么不可信、一个设计方向为什么暂时不值得做。这些 insight 不一定适合立刻写进团队系统,但它们会影响你下一次怎么工作。
另一种是协作的。一个 Pin 可以引用 Linear、飞书、Notion 或 GitHub Issue,把共享上下文带进本地执行现场;也可以在本地被整理好之后,再升级成外部任务或评论。这样,权限和共享仍然由原来的系统负责,而执行上下文由 TermCanvas 承接。
当这个模式和 Hydra headless 结合时,Pin 还能变成集中式流水线的一部分。团队可以在云端运行一套 headless agent 流程,从共享任务系统拉取工作、生成或更新 Pin、分派 agent、回写结果。本地 TermCanvas 仍然可以参与同一条链路:你可以接手一个 Pin,补充证据,调整下一步,或者把本地发现重新送回云端流程。
这不是纯粹的本地优先,也不是纯粹的中心化协作。更准确地说,Pin 是一层可移动的工作记忆:它可以留在个人机器上,也可以接到团队系统里;可以服务于一个人的判断,也可以成为 agent 流水线的输入。
工作方式的变化
一旦保存和交接上下文的成本下降,团队对小工作的处理方式会改变。
我们不再需要在两个坏选项之间选:要么马上做,打断当前任务;要么先不管,之后大概率忘掉。Pin 给了第三种选择:固定住,然后继续当前工作。
这对并行 agent 特别重要。多个 agent 同时跑时,边界比速度更重要。当前任务应该保持窄,旁支发现应该被保存,而不是顺手塞进当前 PR。否则一次改动会慢慢混入测试修复、UI 清理、文档补丁和产品判断,最后变得难审也难回滚。
Pin 让这些旁支有了一个低成本去处:
- review 里发现的跟进项可以独立出来。
- 失败实验可以留下结论,而不是只留下“试过了”的模糊记忆。
- 用户反馈可以带着截图保存,等合适的 agent 接手。
- 一个半成熟的重构方向可以先被探索,而不是立刻变成大改。
更深的变化是心理成本。以前不值得记录的小线索,现在值得保存,因为保存之后真的能恢复。可恢复性改变了我们愿意尝试的范围。
新问题
Pin 也会引入新的问题。
第一个问题是堆积。如果什么都 pin,列表很快会变成另一个收件箱。我们不希望 Pin 成为“以后再说”的黑洞,所以它需要明确状态:open、done、dropped。
done 表示这条线索已经闭环。dropped 同样重要,它表示我们明确决定不继续。很多想法不值得做,但值得保留放弃原因。否则几周后同一个想法会重新出现,再消耗一次判断成本。
第二个问题是边界。Pin 不适合承载大型计划、跨团队排期、合规审批或必须长期追踪的路线图工作。这些仍然应该进入 Linear、飞书、Notion、GitHub Issues 或其他项目管理系统。Pin 更适合介于“现在不做”和“不能丢掉”之间的层:截图、线索、复现步骤、后续动作、agent 可以接手的小任务。
第三个问题是质量。一个模糊的 Pin 只会把模糊延后。我们更鼓励把 Pin 写成可以交接的形式,而不是只写一个标题。它不需要长,但需要足够具体。
我们学到的原则
AI 编码让开发者的工作从单线程执行变成多线程协调。你不只是写代码,也在管理 agent、worktree、终端、PR、测试结果和半成品判断。
在这种工作方式里,稀缺资源不是更多窗口,而是可恢复的上下文。
Pin 的作用就是把上下文固定在项目旁边,让未来的人或 agent 可以从一个明确的恢复点继续。它不是收藏夹,也不是项目管理系统。它是工作记忆:足够轻,可以随手记录;足够结构化,可以重新启动工作;足够贴近项目,不会在下一次切换上下文时散掉;也足够开放,可以连接外部协作系统和云端 agent 流水线。
这也是我们对 Pin 的判断:它的价值不在于保存更多东西,而在于让重要的小工作不再依赖人的短期记忆。