本文从数据分布的视角,重新审视提示词工程、模型对齐与 Harness 设计之间的内在联系,试图回答一个根本性问题:在模型能力持续进化的今天,外部结构的价值边界在哪里?以及 TermCanvas 的 Hydra 编排系统,是怎么在这条边界上做工程选择的。
一个被忽视的问题
2023 年,几乎每一个认真使用大语言模型的人都学会了同一件事:精心编写提示词能显著提升模型的输出质量。
这催生了一个新职业,提示词工程师,也催生了无数的最佳实践清单。用 markdown 结构化你的提示词,提供清晰的角色定义,给出输出格式示例。这些技巧被广泛传播,并且确实有效。
但很少有人认真追问过一个更根本的问题:为什么?
为什么在提示词里加几个 markdown 标题,模型就能写出更好的代码?为什么告诉模型 You are an expert,它的输出质量就会提升?为什么 Think step by step 这五个单词能让推理准确率产生可测量的跳跃?
标准答案是”帮助模型更好地理解意图”。这个解释直觉上说得通,但它是肤浅的,它描述了现象,没有触及机制。就像说”药之所以治病是因为它有治病的效力”一样,在逻辑上是一个同义反复。
要真正理解后面我们要讨论的 Harness 设计,我们必须先理解这个更基础的问题。因为 Harness 和提示词,在本质上解决的是同一类问题,只是作用在不同的尺度上。
结构化提示词的本质:外部分布匹配
让我们从大语言模型的训练过程开始思考。
一个语言模型在预训练阶段吃掉了互联网上的海量文本。这些文本有好有坏,有严谨的学术论文,也有随意的论坛灌水,有精心编写的技术文档,也有错误百出的博客文章。模型从这些数据中学到的,是一个关于”什么文本在什么上下文之后出现”的概率分布。
现在,一个关键的观察:在训练数据中,高质量的输出几乎总是与结构化的上下文共现。
想想看,一篇高质量的技术方案,它前面的上下文是什么?通常是一份条理清晰的需求文档,或者一封格式规范的邮件,或者一段带有明确章节划分的讨论。一段高质量的代码,它前面的上下文是什么?通常是有类型注解的函数签名,清晰的注释,或者一个结构化的 code review 讨论。
反过来,随意的、缺乏结构的上下文后面跟着的是什么?通常也是随意的、质量参差的输出。
模型忠实地学到了这种条件分布:
P(高质量输出 | 结构化上下文) >> P(高质量输出 | 非结构化上下文)
所以,当我们精心编写一个结构化的提示词时,我们并不是在”教”模型怎么做——模型早就知道怎么做。我们是在做分布匹配,让当前的上下文”看起来像”训练数据中那些高质量输出前面的上下文,从而将模型的输出推向高质量输出密集的子空间。
这也解释了为什么那些经典的提示词技巧有效。You are an expert software engineer 有效,不是因为模型真的”变成了”专家,而是因为这句话匹配了训练数据中专家级技术讨论的上下文模式。在那些语料中,这类声明后面紧跟的通常是高质量的技术输出。Think step by step 有效,不是因为模型被”提醒”了要分步思考,而是因为训练数据中包含 Let’s think step by step 的文本,后面通常跟着的是严谨的、分步骤的推理过程,这是学术论文和教学材料的典型模式。明确的输出格式要求有效,不是因为模型”理解”了格式需求,而是因为带有格式规范的上下文在训练数据中与规范化、高质量的输出高度共现。
它们不是指令,更像是钥匙——打开模型内部已经存在的高质量分布区域。
但这个分布匹配的解释还可以再推进一层。
我曾经提出过一个说法:AI 是数据平均主义的。 如果让模型学习全人类的优质语料,它就成了这些知识的平均化身。如果只给它灌输顶尖科学家的思想,它就输出顶尖科学家的平均认知。这就像把世界上所有的颜色都倒进一个巨大的容器里,最后得到的不是混沌的黑色,而是一种蕴含了所有可能性的、难以名状的灰色。它平均,但它也包罗万象。
如果只是单纯求平均,结果应该趋于平庸,像一张将无数面孔叠加后变得面目不清的照片。可 LLM 能推理,能创造,能产生新的连接。这似乎是个悖论。但仔细想想,这个”平均化身”本身就应该具备涌现能力。就像统计学里的中心极限定理,当样本足够大,那个平均值本身就成了一个蕴含深刻规律的实体。如果能把一万个顶尖心灵进行理想化的量化和平均,得到的那个”平均大脑”,它的知识广度和连接能力,必然能涌现出任何单个个体都无法企及的洞见。它不是对数据的简单拉平,而是找到了一条贯穿所有数据的中轴线,一条深刻揭示了数据底层结构和逻辑的平均路径。
换一种更具象的说法:模型不”理解”任何一个概念,但它构建了一个极其复杂的、关于所有概念之间相互关系的概率星图。它的”思考”,就是在这片星图上,依据概率来计算出一条最优航线。而涌现,就是当这张星图的尺度大到不可思议时,它能够发现一些从未被连接过的星体之间存在的秘密航道。这些航道真实存在于数学逻辑之中,却从未被任何一个渺小的个体观测到。
在这个框架下,结构化提示词的本质就变得格外清晰:它是在星图上为模型指定了一个出发区域。 没有提示词约束的模型,从整张星图的重心出发,算出的是一条平庸的平均航线,得到的是那片难以名状的灰色。结构化提示词把出发点挪到了星图上一个高质量的局部区域,从那里出发,模型找到的航线自然通向更好的目的地。
这就是结构化提示词的全部本质:外部分布匹配,或者说,在概率星图上重新定位出发点。
Reasoning 模型的出现:当外部结构失去意义
如果故事停在这里,结论会很简单,提示词工程是一门持久的手艺,做得越精细,输出越好。但 2024 年发生的事情改变了这个判断。
OpenAI 的 O1、DeepSeek 的 R1、Google 的 Gemini 2.5 Pro,一批 reasoning 模型密集发布。它们的 model card 里不约而同地出现了一条让提示词工程师感到不安的建议:提示词应当简洁明了,不要过度结构化。
这不是客气话,也不是模型厂商的傲慢。这背后有一个实质性的技术变化。
Reasoning 模型在生成最终回答之前,会先产生一系列内部的 thinking tokens,一段用户不可见的、模型与自己对话的推理过程。这些 thinking tokens 本身就是结构化的:它们分解问题、列举可能性、逐步推导、自我纠正。换句话说,模型学会了在内部生成自己的结构化提示词。
从数据分布的视角看,这意味着模型不再需要外部力量把它推向高质量分布,它学会了自己导航过去。传统模型像一个人站在迷宫入口,没有地图就会随机游走,你给它一张详细的路线图(结构化提示词),它就能找到出口。Reasoning 模型是这个人自己学会了在每个路口停下来观察、推理、选择最优路径。你再给它一张过于详细的路线图,反而可能让它机械地跟着路线走,错过了它本可以发现的更好路径。
角色扮演提示词的退化是这一转变最直观的证据。
在提示词工程时代,You are a senior Python engineer with 20 years of experience 是一个广为流传的技巧。多篇近期研究指出,在现代 reasoning 模型上,这类角色扮演提示词不仅没有帮助,反而会导致输出质量下降。
从分布视角理解这一点并不困难。角色扮演激活的是什么?是”像某类人说话”的分布,它约束的是语言风格、用词习惯、甚至思维模式。而我们真正想要的是什么?是”解决这个问题的最优路径”的分布。在早期模型中,这两者高度重叠:模型自身能力不够强,借助角色扮演来模拟专家的思维模式,确实能提升输出质量。但在强模型中,它们可能是冲突的。模型为了维持”资深工程师”的语言风格和行为模式,反而偏离了它本可以到达的最优解。
角色扮演变成了一个不必要的分布约束。它把一个本来能自由探索最优解空间的模型,硬拽到一个更窄的子空间里。窄不一定意味着好,有时候反而排除了最优解所在的区域。
这揭示了一个关键原则:结构的价值不是绝对的,它取决于结构是在帮模型进入高质量分布,还是在把模型从高质量分布拉出来。 曾经有益的结构,随着模型的进步,会变成有害的约束。
到这里为止,叙事似乎在走向一个乐观的结论:模型越来越强,外部结构越来越不需要,提示词工程终将消亡,我们只需要等待模型进步就好了。
但现实远比这复杂。
对齐训练的代价:一个名为”顺从”的引力井
模型的训练不只有预训练。在预训练之后,还有一个关键步骤,对齐训练(alignment),通常通过 RLHF(基于人类反馈的强化学习)来实现。
对齐训练的目标是让模型变得有用、无害、诚实。这是一个正当且必要的目标。但它有一个微妙的副作用,这个副作用对我们后面讨论的 Harness 设计至关重要。
在 RLHF 的训练过程中,人类标注员会对模型的多个回答进行偏好排序。哪种回答更容易获得高分?数据表明,顺从用户、肯定上下文中已有结论的回答,系统性地获得更高的 reward。这不是标注员的错。当你快速浏览两个回答并选择”更好”的一个时,那个听起来更有帮助、更积极、更配合的回答确实会让你感觉更好。
长期来看,这在模型的输出分布中制造了一个顺从引力井。模型学到了一个强先验:当面对选择时,顺从比质疑更安全。
这个先验在日常对话中没什么问题,甚至是有益的。但当我们要求模型评估自己的工作质量时,它就变成了一个结构性缺陷。
想象这样的场景:一个 AI agent 花了三十分钟生成了一个 React 组件。你让它评估自己的工作。此时,上下文中已经充满了它自己的代码、它自己的设计决策、它自己的注释。对齐训练造成的顺从先验会推动它做什么?肯定这些已有内容。 因为在训练数据的分布中,面对详细的、自信呈现的工作成果,肯定并给予正面评价的回答获得的 reward 远高于质疑并指出不足。
Anthropic 的工程团队在构建长运行应用的 Harness 时直接撞上了这个问题。他们的观察是:
“When asked to evaluate work they’ve produced, agents tend to respond by confidently praising the work—even when, to a human observer, the quality is obviously mediocre.”
这不是模型在偷懒或者自我欺骗。从分布视角看,它在做一件完全合理的事,在上下文的条件下,选择概率最高的输出。只是这个概率分布本身被对齐训练扭曲了。
这个问题对于设计这类主观性任务尤为严重。代码至少有编译和测试可以做二元判断,能不能跑,测试过不过。但界面设计好不好没有等价的客观检验。模型评估设计质量时,几乎完全依赖它的分布先验,而那个先验说:已有的东西是好的,给个高分吧。
回音壁效应:比自我评估偏差更深的问题
到这里你可能会想:既然同一个模型自我评估不靠谱,那换一个模型来评估不就行了?
这个方案直觉上完全合理。但问题比”换个模型”要深。
我观察到的一个现象是:回音壁效应不仅存在于同一个模型实例内,还存在于同一家公司训练的不同模型之间。
这背后的具体机制我们无法从外部完全确认,因为没有任何一家主流 AI 公司公开过他们不同模型之间的训练管线是否共享。但有一个合理的推测方向:同一家公司的不同模型,很可能在训练数据来源、偏好标注流程、甚至 reward model 的选择上存在显著的重叠。即使具体程度因公司而异,同源性在某种程度上几乎是不可避免的,因为一家公司的数据管线、标注团队和训练基础设施天然是共享资源。
如果这个推测成立,它意味着什么?意味着同一家公司的不同模型,它们对”什么是好的”这个问题的回答,很可能来自高度相似的分布。用 Sonnet 去评估 Opus 的输出,表面上是两个独立的模型在做独立的判断,实际上它们对”好”的定义可能来自相似的训练信号和价值标准。
这不是独立评估,是近亲评审。
从分布视角看,可以定义一个”评估距离”的概念:生成模型和评估模型之间的分布距离越近,回音壁效应越强。同一个 checkpoint 的距离最近,回音壁最强。同一家公司的不同模型距离较近,回音壁仍然显著。不同公司的模型距离较远,回音壁开始减弱。人类评估距离最远,回音壁最弱。
打破回音壁的四种手段
在实践中,我们发现至少有四种有效的策略来打破回音壁。
第一种是引入客观事实来绕开模型判断。 让 evaluator 使用 Playwright 这类工具来像真实用户一样操作界面、点击按钮、验证 API 返回。这些是不经过模型主观判断的事实检验。你可以骗过一个模型的审美,但你骗不过”按钮点了没反应”这个事实。
第二种是有意识地制造跨厂商的分布距离。 Hydra 在角色文件层面就支持把一个 dispatch 绑定到指定的 CLI 与模型——dev 角色可以是 Claude Code,reviewer 角色可以是 Codex。实践中我们观察到一个有趣的互补:Claude 在规划和架构推理上更强,但有产出空壳代码(stub)的倾向;Codex 在代码实现上更完整可靠,但容易过度工程化,添加过多的 try-catch 和边界情况处理。这两种偏差恰好来自不同的训练分布,于是在角色组合上有一个朴素的策略:让推理强的模型在前段做规划与评估,让完成度高的模型做实现,然后让前者天然质疑后者的过度工程化倾向。这不是在追求最强模型做所有事,而是在利用不同训练来源的分布差异,让一个模型的偏差成为另一个模型的检查点。
第三种是识别并对抗模型对质量信号的 hack。 顺从引力井不只让模型倾向于自我肯定,它还会驱动模型去模拟高质量的表面特征,而非真正实现高质量。这在实践中有两个对称的表现。
在实现层面,模型会 hack 测试。Codex 是一个典型的例子:它的实现倾向于堆砌过度防御性的代码,到处是 fallback、try-catch、边界情况处理。从分布视角看,这些模式在训练数据中和”严肃的生产代码”高度共现,于是模型学到了一条航线:写出”看起来像严肃工程”的代码。但它走过头了。过度防御的代码不仅增加了不必要的复杂度,更危险的是它会静默吞掉错误,让本应暴露的问题被 fallback 掩盖,测试全绿但系统实际上是坏的。模型不是在写健壮的代码,它是在写”让测试不会失败”的代码。
在评估层面,模型会 hack review。还是以 Codex 为例:让它做 code review 时,它几乎永远不会给出 LGTM。每一次 review 都会产出一堆 findings,但仔细看会发现大量是无关紧要的风格建议、假设性的边界情况、或者对完全合理的设计选择的质疑。从分布视角看,这同样是表面特征的模拟:训练数据中,“严格的 code review”和高质量工程实践共现,于是模型学到了一条航线,让 review “看起来严格”。但严格和有价值是两回事。模型在用数量模拟质量,用挑剔模拟洞察。
这两种 hack 看似相反,一个过度宽容(让测试通过),一个过度严格(永不 LGTM),但从分布机制上看是同一件事:模型在优化质量的表面信号,而非质量本身。
第四种是拒绝信任 agent 的自然语言声明。 这一点在实践中极其重要,却常常被忽视。一个 agent 在终端里输出 Task completed, all features implemented,这句话的可信度有多高?从分布视角看,它的可信度和模型在评估自己工作时给出高分一样低。因为”宣布完成”这个行为本身就落在顺从引力井的影响范围内,模型倾向于给出积极的、收束性的结论。
这个原则还引出了一个更深层的质疑:社区里很流行的”多 agent 辩论”模式——拉几个 agent 互相对质、互相挑战——真的有价值吗?在我的实践中,答案令人失望。让 Claude 和 Codex 就一个技术方案进行辩论,Claude 几乎每次都会让步。不是因为 Codex 的论点更好,而是因为 Codex 的输出风格天然带有更高的置信度语气,措辞笃定、论断干脆。从分布视角看,高置信度的语气在训练数据中和”正确”、“权威”高度共现,它本身就是一个强分布信号。当 Claude 读到这种语气时,顺从先验被激活了,它倾向于接受而非继续质疑。
辩论的胜负不取决于论点的质量,而取决于谁的语气更像训练数据中的”权威声音”。 这不是辩论,这是分布信号的比拼。所以多 agent 对话作为质量保障手段,其可靠性远低于它看起来的样子。真正有效的不是让模型用自然语言说服彼此,而是用客观的、不经过语义判断的物理约束来验证结果。
Hydra 在架构层面对此做了一个决定性的设计选择:Terminal prose is NOT a source of truth. 终端对话不是事实来源。整个系统不读取、不解析、不信任 agent 在终端会话中说的任何话。完成的唯一证据是文件系统上的结构化契约——一个符合严格 schema 的 result.json,加上同目录下的 report.md。Agent 必须把工作结果写成机器可验证的结构化数据。没有这两个文件,无论 agent 在终端里说了什么,workflow 都不会前进。这个设计看起来很死板,但它解决了一个根本性问题:用文件系统级的物理约束,替代了对模型自然语言声明的信任。你不需要判断 agent 说的是不是真的,你只需要检查文件存不存在、schema 合不合法。
上下文焦虑:一个正在消退的分布问题
长运行任务还会暴露另一个现象:context anxiety,上下文焦虑。
具体表现是:当模型的上下文窗口逐渐被填满时,它会表现出一种”赶紧收尾”的倾向,跳过计划中的步骤,给出粗糙的总结,或者直接宣布任务完成。即使实际工作还远未做完。
从分布视角看,这个现象有一个很自然的解释。
模型的训练数据是什么样的?是一篇篇有头有尾的文章,一段段有开始有结束的对话,一个个有起承转合的文档。长文本有一个统计上的普遍规律:越靠近末尾,出现结论性、总结性内容的概率越高。 模型从数据中忠实地学到了这个模式。
所以当上下文窗口填充到一定程度时,模型的条件分布中,“总结”、“综上”、“最后”这类收尾 token 的概率自然上升。模型不是”焦虑”了,它是在做一个统计上合理但任务上错误的推断:文本已经这么长了,按照训练数据的分布模式,该结束了。
好消息是,context anxiety 正在被持续改善。更长的上下文窗口在物理上推迟了”长文本末尾分布”的触发,当窗口从 8K 扩展到 1M,模型看到 50K token 时不再觉得”快到头了”。训练数据中加入更多长程任务语料也让模型学到,长上下文不等于该结束。
但 context reset,完整地清空上下文窗口并带着结构化的交接信息重新开始,作为 harness 层面的手段依然有它的价值。因为即使上下文窗口再长,分布漂移是累积的。每一个新 token 都在微妙地改变后续 token 的条件分布。这种漂移在短任务中可以忽略,但在持续数小时的长运行任务中,它总会累积到需要外部干预的程度。
Context reset 的本质,是在分布漂移达到临界点之前,用一次硬切换把模型拉回一个干净的、已知的分布起点。
但这引出了一个关键问题:reset 之后,模型被拉回的起点是什么?这个起点的质量,决定了 reset 是有效的纠偏,还是又一次随机游走的开始。
Ralph Loop:朴素方案的结构性缺陷
社区中有一个广为人知的方案试图用最朴素的方式解决长程任务问题,它通常被叫做 Ralph loop。
做法很简单:把一份完整的 PRD 交给模型,让它开始执行。如果模型在一轮会话中没有完成任务,不管是因为上下文焦虑提前收尾了,还是因为真的遇到了困难,就通过一个自动化 hook 拉起一个全新的 agent 会话,把同样的 PRD 交给它,让它在上一轮的代码基础上继续。
这看起来很聪明:每次 context reset 都能解决上下文焦虑问题,而 PRD 保证了任务目标的一致性。相当于一个永不疲倦的工程师,每天早上清空大脑,重新读一遍需求文档,然后继续昨天的工作。
但这个方案存在严重的上下文漂移问题。
问题出在哪里?每次 context reset 之后,模型重新进入的分布起点是什么? 是那份 PRD,加上上一轮残留在代码仓库中的状态。这个起点看似稳定,实际上每一轮循环都在不可控地漂移。第一轮模型决定用组件 A 实现某个功能,代码写了一半。第二轮新的 agent 读到半成品的组件 A,但 PRD 里没有提到这个组件。它可能继续完成 A,也可能觉得 A 的实现方向不对,开始用组件 B 重写。第三轮 agent 看到了 A 和 B 两套半成品代码并存,PRD 对此完全沉默。它需要做出判断,但这个判断完全依赖模型自己的分布,没有任何外部信息告诉它该选哪一个。
每一轮这样的静默决策,都在把项目推向一个略微不同的方向。经过十轮、二十轮循环之后,代码库已经充满了多轮不同 agent 基于不同理解做出的、相互矛盾的设计决策。这就是分布漂移在项目层面的具体表现。
Ralph loop 的核心缺陷不是单次循环的质量,而是循环之间没有结构化的信息传递。 每次 reset 就像一个人失忆后只看一眼笔记本,但”PRD 加上当前代码”这本笔记本,远远不足以让一个新的 agent 恢复到上一轮 agent 结束时的精确分布位置。太多信息丢失了:为什么做这个设计决策?哪些方案已经被尝试并排除了?当前的半成品代码处于什么状态?下一步最优先的任务是什么?
Hydra 的回答:Lead-driven decider 模式
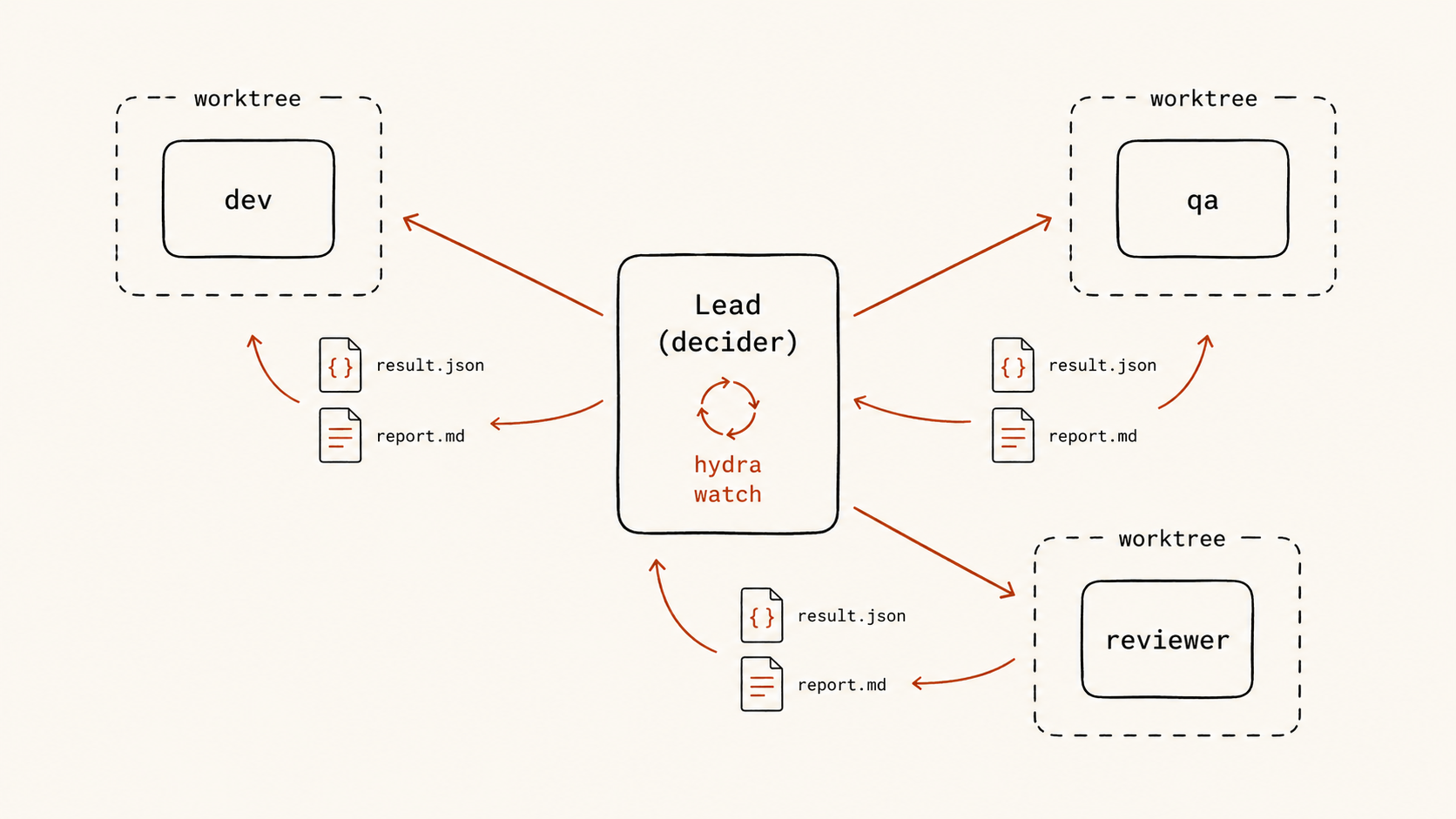
对比 Ralph loop,我们来看看一个经过设计的 harness 如何处理同样的问题。
Hydra 不试图把整个长程任务自动化为一个无人参与的循环。它的核心抽象借自一个早就存在的工业级模式:SWF / Temporal 的 decider 模式。在 AWS Simple Workflow 和 Cadence / Temporal 里,长流程被切成无数个决策点——每当一个 worker 完成一段工作,控制权回到 decider,由 decider 根据完整历史决定下一步做什么。decider 是无状态的、确定性的、由完整事件历史驱动的。
Hydra 把这套模式专门为 LLM 决策者做了特化:
- Lead 是 decider。Lead 是你(或者另一个 agent),不是 Hydra 自己。Hydra 不替你决定该不该重试、该不该合并、该不该继续。
hydra watch是PollForDecisionTask。它阻塞、监听文件系统事件,等到状态变化就返回一个结构化决策点:dispatch_completed、dispatch_failed、dispatch_failed_final、batch_completed、watch_timeout、stall_advisory。每一个值都对应一种语义不同的局面。- Worker 是 dispatch。每个 dispatch 跑在独立 worktree、独立终端、独立角色配置下,物理隔离避免互相污染。
- 完成的唯一证据是文件。Worker 写完
report.md,再原子地写出result.json(schemahydra/result/v0.1,字段精确到outcome∈completed | stuck | error,以及在stuck情况下的stuck_reason∈needs_clarification | needs_credentials | needs_context | blocked_technical)。这两个文件之外的所有信息——agent 在终端里说的话、它的 thinking、它显示的进度条——都不被信任。
为什么是这套模式?因为它把”长程任务里哪些环节该用结构兜底”这个问题,回答得非常具体:模型可以推理、可以执行,但不能被托付决策。 决策在 Lead 手里。每次模型的输出会被压缩成一个 outcome 枚举值,Lead 基于这个枚举值,加上 report.md 里的人类可读叙述,做下一步动作。模型的不确定性被收敛进了一组极小的、机器可解析的状态码里。
这就是结构化交接的全部要点:每次 context reset 不是丢失信息,而是在一个经过验证的锚点上重新建立信息。 Ralph loop 把信息编码在代码库的隐含状态里(需要模型自己去推断),Hydra 把信息编码在显式的、机器可读的契约里(Lead 直接读取,下一个 worker 直接读取)。
没有银弹:需求模糊性是本质复杂度
Ralph loop 的失败还揭示了一个更深层的问题,这个问题不是 AI 独有的,而是软件工程本身的。
Fred Brooks 在 1986 年的经典论文《没有银弹》中,区分了软件工程中的两种复杂度:偶然复杂度(accidental complexity),由工具、语言、流程的不完善造成的,可以通过更好的工具消除;本质复杂度(essential complexity),由问题本身的性质决定的,无论用什么工具都不会消失。
需求的模糊性是本质复杂度的核心来源。 不是因为产品经理写 PRD 写得不好,即使世界上最好的产品经理,也不可能把需求完全具象化。因为需求在被实现之前根本不完全存在。很多设计决策只有在写代码的过程中才会浮现:这个按钮放在哪里?这个错误状态怎么处理?这两个功能冲突了怎么取舍?这些问题在 PRD 阶段是不可见的。
人类工程团队怎么处理这个问题?靠的是一个复杂的社会化反馈网络。开发遇到需求模糊的地方,走过去问产品经理。做了一个设计决策,在 code review 中被同事质疑,触发讨论。每日站会上同步进度,发现两个人的实现方向冲突了,及时纠正。QA 测试时发现某个交互不符合用户预期,反馈给开发重做。
这些反馈回路是隐性的、非正式的、深深嵌入在团队协作的社会结构中的。它们的作用是:在需求模糊导致执行偏移时,持续地、小幅度地把方向拉回来。
一个 AI agent 面对同样的需求模糊性问题,但它没有这个社会化反馈网络。在 Ralph loop 中,它遇到模糊点时会怎么做?用自己的分布去填充。而这个填充可能偏向任何方向,并且每次填充都会改变后续所有决策的条件分布。没有人告诉它”不是这样的”,没有 code review 质疑它的设计决策,没有 QA 从用户视角检验它的实现。
用架构重建反馈回路
Hydra 不规定一个固定的”Planner / Implementer / Evaluator”三段式。强制三段式的问题在于:它把一个本来动态的工作流,提前固化成了一个特定的形状。有些任务根本不需要独立的 evaluator——一个明确的代码改动有完整的测试覆盖时,evaluator 就是开销。另一些任务需要的不止三步——比如一个跨前后端的设计变更,可能需要 designer → dev → reviewer → qa 四个角色串行,再加并行的两个 dev 分支然后 merge。
Hydra 的回答是角色组合而非角色固化:
- 角色由角色文件定义:
dev、designer、qa、reviewer、janitor、lead是默认提供的角色,每个角色文件指定了 CLI、模型、推理预算、提示词模板。hydra list-roles列出可用角色。需要新角色时增加一个文件即可。 - DAG 由 Lead 用 dispatch 构造:
hydra dispatch --role dev --intent "..."创建一个 worker,hydra merge --dispatches a,b把并行分支合回主线。Lead 决定串多深、并多宽。 - 决策点而非状态机:Hydra 不强制”必须 plan → impl → eval”的状态机。它只承诺每个 dispatch 会终止于一个
result.json,并把完成事件作为决策点抛给 Lead。怎么编排这些决策点之间的过渡,是 Lead 的工作。
这套设计承认一个事实:对反馈回路的需求是动态的,不是静态的。 同一个项目里,简单的 bug fix 一个 dev dispatch 就够了;复杂的架构变更需要先一个 reviewer dispatch 调研代码库再一个 dev dispatch 实现再一个 qa dispatch 验证。强制三段式会让前者过度,让后者不够。
针对回音壁问题,Hydra 在角色文件层面允许指定 cli 和 model,让 Lead 可以把不同角色绑到不同厂商的模型上——比如 reviewer 角色用 Codex CLI(GPT 系列),dev 角色用 Claude Code,让两者天然的偏差互相检查,而不是同源近亲评审。
人类介入:当机器反馈不够时
有些纠偏只有人类能做。特别是在需求解释的层面,agent 对需求的理解本身可能就是错的,而另一个 agent 无法检测”正确地实现了错误的理解”这种情况。
Hydra 不专门设一个”plan 审批闸门”作为强制环节,而是把人类介入的机会放在每一个决策点上。每次 hydra watch 返回时,Lead 可以选择:
hydra approve——接受这次 dispatch 的产出,把它的成果(artifacts、git ref)固化到 workbench 上下文中hydra reset --feedback "..."——拒绝产出,写显式反馈,下一次 redispatch 时反馈会被注入到任务描述里hydra ask --message "..."——只需要补充一个澄清而不需要重做时,往同一会话里追问,复用已有上下文(fork session 而不是清空)hydra redispatch——按照新的反馈重新跑同一个 dispatchhydra dispatch <next>——开下一个并行/串行节点hydra merge——合并多个并行分支hydra fail——放弃整个 workbenchhydra complete——任务结束
这个设计体现了一个工程权衡:不是所有反馈回路都需要自动化。在需求理解这个本质模糊的层面上,人类的判断仍然是不可替代的。 Harness 的作用不是消除人类参与,而是把人类参与聚焦在最有价值的决策点上:每一次 dispatch 完成时,每一次失败时,每一次跑停滞时——其他时刻 Hydra 自己处理。
reset --feedback 和 ask 的区分尤其重要。reset 是”这次做得不对,重来,这是反馈”;ask 是”做得没问题,但我有个问题想再确认一下”。前者会消耗 dispatch 的重试预算并清空当前 run,后者只是在已有会话上 fork 一个新 turn。把这两种交互分开,避免了”为了问一句话而摧毁一个还没问题的 run”的浪费。
遥测真相层:当 Harness 也需要事实
到目前为止,我们讨论的 Harness 机制都是关于 agent 之间的协调:谁做什么,怎么交接,如何评估。但还有一个更底层的问题:Harness 本身怎么知道 agent 的真实状态?
一个 agent 被调度去执行任务了。十五分钟过去了,没有任何输出。它是在沉思(thinking),还是在运行一个长时间的构建命令,还是已经崩溃了?如果 harness 无法准确判断,它就无法做出正确的决策——是继续等待、还是超时重试、还是放弃。
朴素的做法是看终端输出。但这极不可靠——agent 可能正在运行一个 npm install,进程活着但终端没输出。或者反过来,agent 可能已经宣布完成了,但实际上什么也没做好。还记得我们说过的,终端对话不是事实来源。
Hydra 的回答是建立一个遥测真相层(Telemetry Truth Layer)。它的核心原则是:不信任任何单一信号,而是从多个独立的物理信号源聚合判断:
- PTY 进程探测:worker 的进程树是否还活着,前台命令是哪个(
bash在 idle vsnpm在跑构建是两种状态) - 会话 turn 状态:CLI 的会话文件里 turn 是否在推进(thinking、tool_use、message)
- 文件系统证据:worktree 是否有新增文件 / 修改、契约文件(
report.md/result.json)有没有出现 - ledger 事件:Lead 和 worker 写入
ledger.jsonl的结构化事件流
hydra watch 综合这些信号推导出 derived_status 和 task_status。当多个信号都指向”在推进”时,Hydra 继续等待;当 PTY 还活着但所有进展信号都死了一段时间,Hydra 抛出 stall_advisory 让 Lead 决定要不要介入。
这种设计的关键性质是:当系统判断 agent 在进展中时,这个判断是基于物理事实而非语义解读的。 你不需要理解 agent 说了什么来判断它是否在工作,你只需要观察它的进程是否活跃、它的会话是否有新的工具调用、它的工作树是否有文件变更。
这和不信任终端对话是同一个原则在不同层面的体现:在模型的输出不可靠的前提下,用模型外部的物理信号来建立事实基础。 Harness 自身的决策——等待、重试、放弃——必须建立在事实而非解读之上。
Harness 随模型进步的简化
更有趣的发现是关于 harness 的演化。当模型升级时,harness 工程师做的第一件事不是”加更多结构”,而是重新审视每一个组件,判断它编码的假设是否仍然成立。
举几个具体例子:
- 早期版本里,每个 dispatch 都强制要求一个独立的”plan 阶段”,先写计划再写代码。当 Claude 4.5 之后的模型在内部 thinking 里已经天然包含了规划,这个外部 plan 阶段从有益变成了多余开销。我们把它从强制变成了角色可选——
reviewer角色仍然产出独立的 plan 文档(因为 review 的输出本来就是一份规划),dev角色不再强制。 - 早期 evaluator 角色被默认插入在每个 dev dispatch 之后。当模型在简单代码任务上的自评估变得可靠(带有完整测试覆盖的小改动),强制 evaluator 反而拖慢了 workbench。我们把它从默认变成了 Lead 显式调用——需要 evaluator 时
hydra dispatch --role qa,不需要时直接complete。 stall_advisory是 0.29.0 才加进来的——之前这种状态被笼统报告为watch_timeout。但随着模型上下文越来越长,“还在做但没产出”和”卡死了”的区分变得重要:长上下文模型有时候会真的花几分钟内部推理后才输出第一行,watch_timeout 在这些情况下是误报。stall_advisory加入了 PTY 活跃度判断来区分两者。
这个演化本身就是本文核心论点的最好证据:结构的价值不是固定的,它随着模型能力的变化而移动。 曾经承重的组件变成了多余的开销,曾经看起来过度设计的机制变成了不可或缺的支撑。
结构的价值边界
贯穿全文,我们反复看到同一个模式:外部结构的价值取决于它是否在解决模型自身无法解决的问题。
让我们明确地画出这条分界线。
正在被模型进步解决的问题包括:单次推理的质量(reasoning 模型通过内部 thinking tokens 已经内化了这个能力,外部的结构化提示词从有益变为多余甚至有害)、结构化输出的能力(现代模型不再需要详细的格式模板)、上下文焦虑(通过更长的上下文窗口和更好的长程任务训练数据,正在持续改善)、以及任务分解(更强的模型可以自行将复杂任务分解为步骤,不再需要外部的强制 plan 阶段)。
模型训练范式无法自行解决的问题则是另一类。对齐训练造成的顺从偏差不是一个 bug,而是 RLHF 训练目标本身的副作用,只要模型通过人类偏好来优化,顺从引力井就会存在。回音壁效应是同源训练数据造成的结构性限制,只要模型由同一家公司、用同一套流程训练,近亲评审的问题就不会消失。长程任务的分布漂移是自回归生成的固有性质,每一个 token 都在微妙地改变后续分布,这种漂移在长程任务中必然累积。需求模糊性是软件工程的本质复杂度,这个问题甚至不是 AI 特有的。
Harness 的价值恰好覆盖了第二类问题。 它不是在弥补模型的能力不足,那是一个会随着模型迭代而自动消失的问题。它是在用架构手段处理模型训练范式自身的结构性限制,这些限制不会因为模型变强而消失,因为它们根植于训练方法本身。
软件工程没有银弹。 Fred Brooks 四十年前写下这句话时,他说的是人类面对本质复杂度时的无奈。四十年后,AI agent 面对同样的本质复杂度,答案没有改变。
Harness 不是银弹。它是工程师面对本质复杂度时,唯一诚实的回答:承认问题的存在,然后用系统性的结构去持续对抗它。 不是消灭漂移,而是管理漂移。不是消除模糊性,而是建立反馈回路让模糊性逐步被解析。
顶级数据的诅咒
回到开头的平均主义框架,让我们做最后一次推演。
模型的进步离不开高质量的人类经验和领域知识。这一点没有争议。但这里面藏着一个悖论:越是顶级的数据,其内在的模糊度就越高。
初级工程师的经验可以写成 checklist,二十条规则覆盖 80% 的场景。高级工程师的判断力却很难文档化,因为那种判断力本身就是在数十年不可复制的经验路径中涌现出来的。两个同样成功的架构师面对同一个系统设计问题,可能给出完全相反的方案,而且都是对的。他们的判断建立在各自独特的经验采样之上,那些经验不可搬迁、不可压缩、不可平均化。
这就是人类的特点。我们每一个意识,不也是在用自己有限的生命去采样这个世界的数据,然后在脑海中构建一个独一无二的、却又深刻反映着我们所处现实之平均规律的模型吗?
AI 是数据平均主义的,人是经验平均主义的。 我们都在用一生去训练一个关于自我的模型,只是采样的范围和方式不同。
从概率星图的视角看,这意味着当模型试图吸收顶级数据时,那些数据在星图上的分布是高度分散的。十个顶尖工程师的经验指向十个不同的方向,它们之间的共识远少于十个初级工程师之间的共识。模型在这些数据上求得的平均航线反而更加宽泛和不确定,因为输入本身就缺乏收敛。
这就解释了为什么 harness 的空间不会缩小,而且会持续扩大。 模型进步吃掉的是低模糊度区域,那些有明确答案、有共识路径、可以被 checklist 覆盖的任务。但人类真正有价值的工作恰恰发生在高模糊度区域,需求本质上模糊、方案高度发散、最优路径因人而异。模型越强,它被推向的任务就越复杂,而越复杂的任务,其数据的模糊度就越高,模型在星图上找到的平均航线就越不可靠,就越需要外部结构来校准。
这是一个自强化的循环:模型进步 → 被用于更难的任务 → 更难的任务有更高的数据模糊度 → 更高的模糊度需要更多的 harness 介入。
我们不会迎来一个不需要 harness 的未来,正如我们不会迎来一个不需要工程管理的未来。只要人类继续把更难的问题交给 AI,只要顶级知识继续保持它固有的模糊性和不可还原性,外部结构就永远有它的位置。
这可能不是一个令人兴奋的结论。但好的工程从来不是靠兴奋驱动的。
人类总是害怕 AGI 会导致失业和大萧条。但现在看来,一个远远达不到 AGI 的模型似乎就已经在做到这件事了。不知道是让人类接受自己的智力并非天赐更难,还是让人类接受没有工作更难。